 阿摩線上測驗
阿摩線上測驗
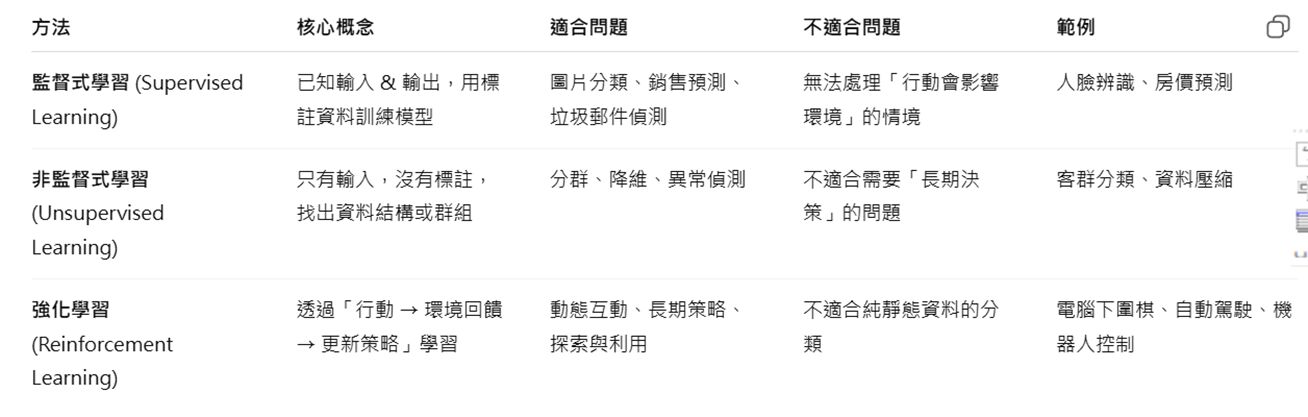
1 下列何者最適合訓練電腦下圍棋、自動駕駛等動態重複地互動的問題?
(A) "監督式學習 (Supervised Learning)"
(B) "非監督式學習 (Unsupervised Learning)"
(C) 半監督式學習 (Semi- supervised Learning)
(D) "強化學習 (Reinforcement Learning)"
答案:登入後查看
統計: A(37), B(12), C(14), D(508), E(0) #3434874
統計: A(37), B(12), C(14), D(508), E(0) #3434874
詳解 (共 3 筆)
jacky chou
#6603041
在訓練電腦下圍棋、自動駕駛等動態重複互動的問題中,最適合的學習方法是:
(D) 強化學習 (Reinforcement Learning)
理由
- 強化學習 是一種通過與環境互動來學習的方式,系統會根據行動的結果獲得獎勵或懲罰,從而調整其策略以最大化長期獎勵。
- 在圍棋和自動駕駛中,這些系統需要不斷地進行決策,並根據環境的變化來調整行為,這正是強化學習的強項。
其他選項的適用性:
- 監督式學習:需要標記數據,主要用於靜態問題。
- 非監督式學習:用於從未標記數據中尋找模式,對於動態互動的場景不太適合。
- 半監督式學習:結合了監督式和非監督式學習,但仍不如強化學習適合於動態互動的環境。
2
0
SUYA88888888
#6630969
依據CHATGPT 的回覆: 由於圍棋是用於解決動態互動 長期策略 探索與利用 不適合純靜態資料分類 等監督非監督式學習,適合強化學習。
0
0