所屬科目:教甄◆資訊科
1.假設有五個程序P1,P2,P3,P4,P5的優先權(1比5優先)及所需計算時間(秒)如下表;作業系統(單CPU)使用優先權排程演算法,試問這五個程序的平均等待時間(秒)?(A)2.3(B)3.4(C)4.5(D)5.6(E)6.8
2.請計算下列後序表示法(Postfix)正確答案為何?後序表示法(Postfix):
(A)-130(B)130(C)6(D)38(E)124
3.下列有關IPv4及IPv6的差異敘述,何者「有誤」?(A)IP位址的長度,IPv4是32位元,IPv6是128位元(B)和IPv4相同,IPv6的IP表頭(Header)中亦有Checksum欄位(C)不同於IPv4,IPv6內建加密機制,具有更好的安全與保密性(D)兩者IP表頭(Header)中,IPv4之欄位TimetoLive與IPv6之欄位HopLimit意義相同
4.使用圖片訓練機器學習模型,將所有圖片分成不同資料集,其中專門用於檢測模型對沒遇過圖片的表現,為以下何者?(A)訓練集(trainingdataset)(B)驗證集(validationdataset)(C)測試集(testdataset)(D)子資料集(subdataset)
5.以下哪個指令可以條列出區域網路內多台主機的IP與MAC的對應?(A)nslookup(B)netstat(C)arp(D)tracert
6.以下哪種技術是生成式人工智慧中常用的技術,請選出最適合的答案?(A)支持向量機(SupportVectorMachine)(B)Transformer模型(C)隨機森林(RandomForest)(D)決策樹(DecisionTree)
7.以下何者屬於非監督式學習?(A)K-means分群(B)線性迴歸(LinearRegression)(C)決策樹(DecisionTree)(D)支持向量機(SupportVectorMachine)
8.使用堆疊(stack)資料結構,已知A、B、C、D、E、F以此順序依序存入堆疊,則下列何者「不可能」為這六個元素離開堆疊的順序?(A)A、B、C、D、E、F(B)A、E、F、D、B、C(C)D、F、E、C、B、A(D)F、E、D、C、B、A
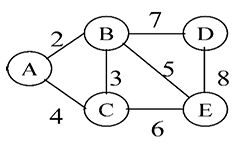
9.以下為一個含六個節點的圖,在圖上任選一點進行深度優先搜尋(DFS),「不可能」產生下列哪一種走訪順序?(A)AECDBF(B)FAEDCB(C)ECBADF(D)AEFCDB
1.當一台電腦透過瀏覽器造訪Google(https://www.google.com/)網站時,該電腦可能會引發哪些通訊協定?(A)DNS(B)TCP/IP(C)HTTP/HTTPS(D)SMTP(E)FTP
2.以下哪種排序演算法在所有情況下都能保證O(nlogn)的時間複雜度?(A)快速排序(QuickSort)(B)堆積排序(HeapSort)(C)合併排序(MergeSort)(D)插入排序(InsertionSort)
3.在圖論中,以下有關Kruskal演算法與Prim演算法的說明哪些是正確的?(A)Kruskal以邊為基礎選擇,Prim以頂點為基礎選擇(B)Kruskal使用貪婪法,Prim使用動態規劃(C)Kruskal適合稀疏圖,Prim適合稠密圖(D)都是用來處理最大生成樹
4.下列有關網路的說明,哪些是正確的?(A)在TCP連線終止過程中,最後一個封包是ACK(B)在計算機網路中,ICMP協定主要負責IP封包的尋址與轉送(C)TCP協議提供二次握手特性以實現可靠數據傳輸(D)UDP適用於實時性要求高的場景,如視頻直播和在線遊戲
5.以下有關資料科學的說明,哪些是正確的?(A)Spark使用磁碟進行數據存取,Hadoop主要使用記憶體(B)關聯式數據庫適用於高度結構化型應用(C)PCA可以用來降維,是因為找到數據的主要變異方向,投影到較少的維度來保留主要資訊,降低計算成本(D)大數據分析,最常用的資料清洗技術包括刪除異常值和標準化
6.以下敘述何者正確?(A)在記憶體層級架構,如:DRAM、SRAM、SSD、HDD中,DRAM的存儲裝置具有最快的存取速度(B)IPv6使用256位元的位址(C)在資料結構中,堆疊(Stack)結構最適合用來實作遞迴演算法(D)在人工智慧領域,非監督式學習不需要人工標註的訓練數據
第三大題:填充題
1.請觀察下方程式碼:
請問最後印出的a值為何?__________。
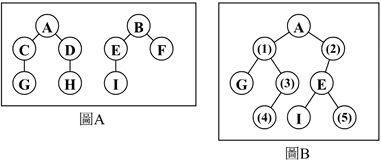
2.下圖A代表兩個「樹」的「森林」,利用左子右弟(Left-ChildRight-Sibling)方法,可將森林轉換為圖B的二元樹,則(1)、(2)、(3)、(4)、(5)分別代表________________。
3.A[m][n]為二維陣列,假設A陣列以列為主(RowMajor)排列,每個元素佔用一個記憶體位址,A[3][3]在記憶體中的位址為121,A[6][4]在記憶體中的位址為161,則A[1][1]在記憶體中的位址為何?________________。
4.下圖中的最小生成樹(Minimumspanningtree)的成本為____________。
5.若F=A⊕B,⊕為XOR運算
當A=11011001,B=01100001時,F之結果為何:_____________。
6.執行以下C++程式輸出結果為何?_____________。
7.執行以下C++程式輸出結果為何?_____________。
8.機器學習模型對於訓練資料有很好的預測結果,但對於測試資料預測結果不佳,稱作_____________。
9.有一個二元樹(binarytree),其後序走訪(post-ordertraversal)為AFECGDB,中序走訪(inordertraversal)為AEFCBGD,請問此二元樹的前序走訪(pre-ordertraversal)結果為何?_____________。
10.資料結構的優先佇列(PriorityQueue)通常使用哪一種資料結構進行實作?_____________。
11.生成式人工智慧的生成對抗網絡(GAN)由哪兩部分組成?_____________、_____________。
12.下面的程式碼計算兩個陣列的交集(共有元素的數量),假設兩個陣列各自都沒有重複的元素。它計算交集的方法是對一個陣列(陣列b)進行排序,然後迭代陣列a檢查每個值是否出現在陣列b中(透過二元搜尋)。請問它的執行時間是多少(時間複雜度)?_______________。
13.PageRank演算法在搜尋引擎中的作用是什麼?____________________。
(a)利用深度優先搜尋DFS(DepthFirstSearch)方法,走訪的順序為何?
(b)利用廣度優先走訪BFS(BreadthFirstSearch)方法,走訪的順序為何?
(c)請畫出無向圖G。
五、何謂過度擬合(Overfitting)?可能是甚麼原因造成?如何解決?
六、假設想要分析YouBike在哪一個時間點哪一個站點,會出現無車可借或無位可還,以此結果事先進行車輛調度,減少此狀況。如果你是資料科學家,完成此分析的工作流程為何?
 阿摩線上測驗
登入
阿摩線上測驗
登入
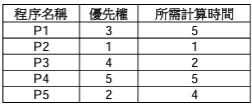 (A)2.3(B)3.4(C)4.5(D)5.6(E)6.8
(A)2.3(B)3.4(C)4.5(D)5.6(E)6.8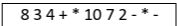 (A)-130(B)130(C)6(D)38(E)124
(A)-130(B)130(C)6(D)38(E)124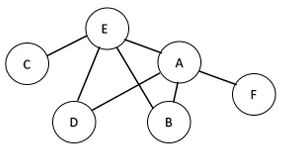 (A)AECDBF(B)FAEDCB(C)ECBADF(D)AEFCDB
(A)AECDBF(B)FAEDCB(C)ECBADF(D)AEFCDB