 阿摩線上測驗
阿摩線上測驗
三、傳統上,進行文件檢索的評分時,採用的是 recall(查全率)與 precision (查準率),這是一種適用於無排序之檢索結果(non-ranked retrieved list) 的評量尺度。然而,多數的資訊檢索系統的檢索結果都是排序的,這也符合使用者的期待,畢竟第 1 篇文件就是相關文件,與第 20 篇文件才是相關文件,對使用者而言,感覺是截然不同的。試說明並舉例資訊檢 索的評價指標 MRR、MAP 和 NDCG。(25 分)
詳解 (共 1 筆)

GPT老師的神之解釋(超級清楚)
三個常見排序型檢索評估指標:1️⃣ MRR(Mean Reciprocal Rank,平均倒數排名)
? 舉例:如果三次查詢中,正確答案分別出現在第 1、2、4 名 2️⃣ MAP(Mean Average Precision,平均精準率)
舉例:如果有三篇相關文件出現在第 2、4、5 名,那 precision 分別是: 3️⃣ NDCG(Normalized Discounted Cumulative Gain,標準化折扣累積增益)
舉例(簡化):你希望「高度相關的資料」能排前面 ✅ 結語整理(可寫在申論末段):MRR、MAP、NDCG 都是用來評估排序資訊檢索系統的精準度與排名品質。 |
||||||||||||||||||||||||||||||||
|
#口語說明
MRR(平均倒數排名)是什麼?你可以想成:
關鍵詞:看「第一個有用的結果」,越早出現越好。 MAP(平均精準率)是什麼?你可以想成:
關鍵詞:整體來看,正確答案有沒有集中排在前面。 NDCG(標準化折扣累積增益)是什麼?你可以想成:
關鍵詞:不只是對或錯,還考慮「多相關」跟「排多前面」。 總結一句話口語版:
|
||||||||||||||||||||||||||||||||
|
#MRR、MAP 和 NDCG的舉例以及公式
ㅤㅤ
1. MRR(Mean Reciprocal Rank)平均倒數排名
舉例:3 筆查詢的正確答案出現在:
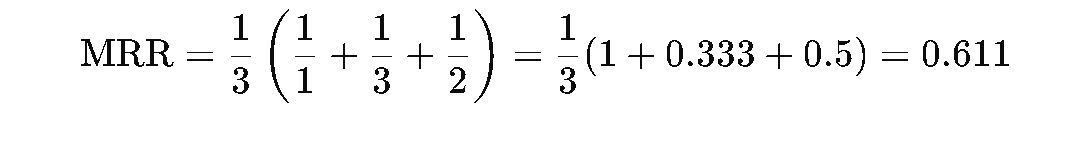 ㅤㅤ
2. MAP(Mean Average Precision)平均精準率
舉例:查詢結果:「相關資料」在第 2、4、5 名。總共 3 筆正確答案。
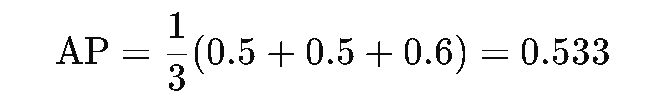 ㅤㅤ
3. NDCG(Normalized Discounted Cumulative Gain)標準化折扣累積增益
ㅤㅤ
ㅤㅤ
ㅤㅤ
ㅤㅤ
ㅤㅤ
ㅤㅤ
ㅤㅤ
ㅤㅤ
|
||||||||||||||||||||||||||||||||
總結對比表:
ㅤㅤ
ㅤㅤ
ㅤㅤ
|
||||||||||||||||||||||||||||||||
#我的疑問為何 MAP查詢結果:「相關資料」在第 2、4、5 名。總共 3 筆正確答案。
第 2 筆:Precision = 1/2 = 0.5
第 4 筆:Precision = 2/4 = 0.5
第 5 筆:Precision = 3/5 = 0.6
分子不是 第 2 筆:Precision = 1/2 = 0.5 第 4 筆:Precision = 1/4 = 0.5
第 5 筆:Precision = 1/5 = 0.6
而是123呢 ㅤㅤ
GPT解答們來逐步拆解這個概念:假設查詢結果排序如下(前 5 筆):
ㅤㅤ
✅ 出現在第 2、4、5 筆(共 3 筆正確答案)。 ? AP 的計算邏輯是:每當我們遇到一個「正確答案」,就:
✅ 所以:
⛔錯誤理解(你提出的)是:
這樣的計算忽略了「這是第幾個正確答案」,以及「前面有幾筆是對的」,而 Precision 的分子其實是「累計的正確答案數」。 ✅簡易總結:
ㅤㅤ
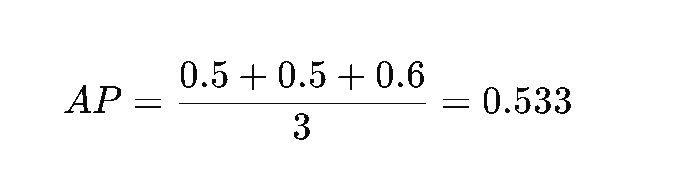 ㅤㅤ
ㅤㅤ
ㅤㅤ
|
||||||||||||||||||||||||||||||||
#若在考試時遇到完全不懂的名詞✅ 一、關鍵策略:拆字理解 + 邏輯推測 + 比較分析即使不知道定義,也盡可能寫出以下內容: 1. 拆字解釋字面意義(分數保底)
✅ 你可以這樣寫(模擬考場語氣):
✅ 二、延伸應對策略:套用一般資訊檢索知識即使不熟名詞,這類題目通常還是跟:
有關,你可以補充:
✅ 三、千萬不要空白,以下是你最低保底策略:如果真的完全沒看過這些詞,寫個通則型答案仍然可得分:
?總結:考試遇不熟名詞怎麼辦?
ㅤㅤ
✅ 一、不要空白,靠「推理+相關知識」搶基本分!考試不是死背名詞競賽,而是考你:
? 解題策略如下:1. 承認不熟,展現邏輯你可以開頭誠實說明:「雖未熟悉 MRR、MAP、NDCG 的詳細定義,但根據資訊檢索常見的指標邏輯,可做以下推測與推論。」 然後寫:
✅ 二、補充「通用資訊檢索原則」作為內容骨架即使不知道縮寫意義,也可從以下角度展開回答:
ㅤㅤ
✅ 三、提出合理應用情境來補分你可以舉例:
✅ 實用範例:考場可寫這樣
這樣的回答即使不完全正確,也展現出你的邏輯能力與資訊素養,有望拿 一半以上分數(約12–15分)。 ? 建議你:事前背熟這三個縮寫對應的英文與概念:
|
GPT釐清觀念
你說的(我說的可能是錯得):
MRR:不同查詢尋找正確答案比率
MAP:相同搜尋正確答案出現率
這樣的說法接近核心,但詞彙需要更精確,否則在考試或實務中可能會造成誤解。
✅ 正確說法如下:
? MRR(Mean Reciprocal Rank)
重點在「第一個正確答案的位置」
-
每一筆查詢只看第一個正確答案在哪裡(排第幾)。
-
然後取「排名的倒數」(例如排第2名 → 1/2)。
-
最後將所有查詢的倒數排名「平均起來」。
? 適用情境:
-
當使用者只需要一個正確答案時(例如:問答系統、FAQ搜尋)
? 你可以理解成:「每筆查詢中,第一個正確答案出現的平均位置」
? MAP(Mean Average Precision)
重點在「多個正確答案的精準率」
-
每筆查詢可能會有多個正確答案(例如:搜尋「文學批評」,可能有10本相關書)。
-
計算每次正確答案出現時的精準率(Precision),然後平均起來。
-
最後再把多筆查詢的平均精準率再平均 → 得到 MAP。
? 適用情境:
-
使用者可能需要多個相關項目(例如:學術文章搜尋)
? 你可以理解成:「一筆查詢中,每次正確結果出現時的精準率,然後多筆查詢平均」
✅ 快速對照表
| 指標 | 簡單解釋 | 適用情境 |
|---|---|---|
| MRR | 第一個正確答案出現的平均位置(倒數) | 問答系統、FAQ、快速查詢 |
| MAP | 多個正確答案的平均精準率 | 學術搜尋、多結果系統 |
✅ 小提醒:不是「不同查詢 vs 相同查詢」
你說的「不同查詢 vs 相同查詢」會讓人以為 MAP 是用同一筆查詢重複測試,其實不然,兩者都會針對多筆不同查詢來計算平均,只是衡量指標不同:
-
MRR:重視第一筆正確結果的排名
-
MAP:重視每筆查詢的整體精準率平均
✅ 建議你這樣記:
? MRR:只要一個答案快快出現就好(重排名)
? MAP:答案愈多愈好,而且每個都要出現在對的位置(重精準率)