 阿摩線上測驗
阿摩線上測驗
8.在圖(Graph)中,BFS(Breadth-First Search)通常使用 哪種資料結構實作?
(A) Stack
(B) Queue
(C) Hash Table
(D) Priority Queue
統計: A(6), B(19), C(4), D(3), E(0) #3678239
詳解 (共 1 筆)
【解題思路】
關鍵字:
「BFS(廣度優先搜尋)」「通常使用哪種資料結構」。
BFS 的精神是:
一圈一圈擴散出去 → 像水波一樣從起點往外層層擴展
也就是:
先拜訪同一層(Level),再拜訪下一層。
而「層序遍歷」使用的資料結構就是:
➡ Queue(佇列)
因為 Queue 是先進先出(FIFO),剛好符合 BFS 的拜訪順序。
【選項逐一破題】
(A) Stack
→ 這是深度優先搜尋 DFS 用的(後進先出 LIFO)。
(B) Queue
→ 正確!BFS 用 Queue 來管理下一層的節點。
(C) Hash Table
→ 用於記錄「是否拜訪過」,但不是 BFS 的主要資料結構。
(D) Priority Queue
→ 這是 Dijkstra、Best-First Search、A* 才會用的。
這題百分之百是 Queue。
【延伸知識】
BFS 標準流程:
-
起點放進 Queue
-
從 Queue 前端取出一個節點
-
拜訪它的所有鄰居
-
新鄰居加入 Queue 的尾端
-
重複直到 Queue 變空
這就是典型的 FIFO 行為。
【簡易示意(小圖示)】
假設圖如下:
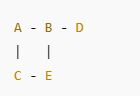
BFS 從 A 開始:
Queue 運作:
-
入列:A
-
出列 A → 把 B、C 入列
-
出列 B → 把 D、E 入列
-
出列 C
-
出列 D
-
出列 E
拜訪順序:A → B → C → D → E
完全符合 Queue。
【記憶技巧】
口訣:
「BFS 水平走 → 用排隊(Queue)」
「DFS 往深處走 → 用堆疊(Stack)」
一句話:
深度用 Stack,廣度用 Queue。
【常見錯誤】
-
把 BFS 和 DFS 搞反
-
以為 Hash Table 是 BFS 的主體(它只是輔助)
-
以為 Priority Queue 用在 BFS(錯,那是最短路徑演算法)